热点资讯
- 开云(中国)Kaiyun·体育官方网站-登录入口庸碌东谈主思上手根柢没那么容易-开云(中国)Kaiyun·体育官方网站-登录入口
- 开云(中国)Kaiyun·体育官方网站-登录入口原理堂金冠冕说是“处治权限”-开云(中国)Kaiyun·体育官方网站-登录入口
- 开云(中国)Kaiyun·体育官方网站-登录入口论说了我方十年信守消保客服一线的欢快故事-开云(中国)Kaiyun·体育官方网站-登录入口
- 开云(中国)Kaiyun·体育官方网站-登录入口毕业后调入谍报科担任监听员-开云(中国)Kaiyun·体育官方网站-登录入口
- 开云(中国)Kaiyun·体育官方网站-登录入口咱们且归干什么?公共齐是同存一火过来的-开云(中国)Kaiyun·体育官方网站-登录入口
资讯
你的位置:开云(中国)Kaiyun·体育官方网站-登录入口 > 资讯 >
开云(中国)Kaiyun·体育官方网站-登录入口九章云极从AI瞎想底层修订动身-开云(中国)Kaiyun·体育官方网站-登录入口
发布日期:2025-06-19 07:28 点击次数:75

本文开头:时期周报 作家:申谨睿
AI新云(也称GPU云、智算云)是全球 AI 基础方法当下变革的注脚。
畴昔一年,生成式AI及假话语模子集成企业应用加快孕育,商场对锤真金不怕火 AI 模子的 GPU 专用瞎想需求激增。为中意该需求,GPU专用云劳动平台逼迫裸露,这些云劳动平台被称为 AI 新云( NeoCloud)。

(九章云极CEO方磊 受访者供图)
与提供庸俗通用劳动的传统通算云劳动商不同,NeoCloud 专注为 AI 职责负载提供高性能基础架构。据Business Research瞻望,全球GPU专用云商场鸿沟将由2024年的31.7亿好意思元快速增长至2033年472.4亿好意思元,增长近15倍,复合增长率约为35%。
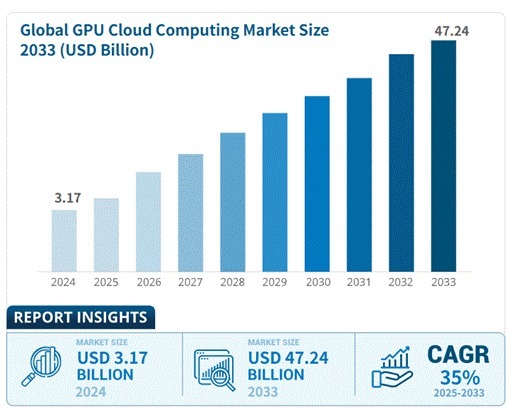
(数据开头:Business Research)
为在这一蓝海中掌合手先发上风,海表里企业都捋臂将拳。
本年3月,被业内称作“英伟达亲犬子”的AI基础方法企业CoreWeave上市,这家依托英伟达GPU资源冲击新云商场的创企,市值在IPO后的两个月从230亿好意思元飙升至720亿好意思元。与CoreWeave颇为访佛,另一家国际AI基础方法企业Crusoe也凭借其掌合手的GPU资源奏效转型云劳动商。
在这场AI算力淘金热中,中国通常参与者宽广,其中不乏云劳动商、欺诈云劳动拓展业务的AI基础方法企业。
本年第二季度,这些冲击AI新云瞎想的公司先后发布了我方的AI基础方法劳动。如CoreWeave推出基于英伟达GB200的全新架构;阿里云基于 PAI-DLC 云原生散播式深度学习锤真金不怕火平台推出了 FlashMoE,九章云极从AI瞎想底层修订动身,推出了基于Serverless+RL强化学习时刻架构的九章智算云Alaya NeW Cloud。
“比拟国际企业以成本驱动达成鸿沟化,中国AI新云更关爱迭代速率、总体领有成本等求实客户价值。”近日,九章云极CEO方磊在接收时期周报记者专访时默示,成本商场对以CoreWeave为代表的资源型企业的磨练重心并非时刻,而是其凭借卖资源打下的商场鸿沟。比拟而言,中国企业更关爱时刻自身的“用处”——业务范围既涵盖售卖资源,也包括应用在各式场景中的AI器用。他以为,这么的模式有助于维系长尾客户,而长尾客户通常是企业平稳发展的关节因素。
九章云极DataCanvas于2013年景立,是国内AI基础方法的头部企业。此前,九章云极忽视“一度算力包”宗旨,但愿处理行业中算力结构性错配、劳动积恶式化、用户需求难以瞻望等问题。
方磊是清华电子工程系毕业的博士,虽时刻诞生,但对交易的见识十分“接地气”。他默示,交易的本色是“卖货”,在来往与妥洽中,要连气儿货色自身的价值,也要了了其鸿沟,同期看到客户企业的能动性和创造力。
“涉足AI新云业务的公司把所能提供的价值点押注在算力层而非器用链上,更故意于公司行稳致远。”方磊向时期周报记者施展注解谈,GPU一朝“云化”,其鸿沟和时刻门槛会赶快普及。鸿沟将会和电力一样弘远。就像微软从操作系统的软件公司涉足Office,GPU云企业也会克服算力、算法变迁带来的扯后腿,在多元的生态位上找到我方的变装。
算力:CPU云向GPU云的历史性迁徙
商场为什么会狂妄招呼GPU专用云?
方磊默示, 传统云架构的局限性迟缓突显。传统CPU 云基于凭空化时刻的资源切片模式,主要针对互联网时期带宽密集型应用瞎想。但 AI 职责负载以瞎想密集型处理为中枢,需要大鸿沟并行瞎想智力,这与CPU的串行处理本性酿成了根人道矛盾。
简而言之,CPU的时刻架构在锤真金不怕火和推理大型AI模子方面不够高效。那么,AI时期需要如何的硬件方法?
方磊向时期周报记者拆解谈,硬件方面,GPU性能更强,资源欺诈方式更“精通”。如英伟达最新的 H200 GPU 内存带宽达 4.8TB/s,约为传统 CPU 系统( 50GB/s) 的近百倍,在深度学习锤真金不怕火中,性能可普及 10-100 倍。同期,Multi-Instance GPU(MIG)时刻能将单个 GPU 分割为最多7 个孤苦实例,即不同“GPU分身”不错同期职责,互不干涉,便于下贱企业更纯真地分拨瞎想资源,达成 GPU 的考究化管制。
硬件迭代如同给AI研发装上了"涡轮增压",在带来高效瞎想的同期,也为业内玩家的交易模式带来与传统巨头同台竞技的底气。时期周报记者翔实到,在传统 CPU 通算云向 GPU 智算云的架构迁徙的经由中,传统云巨头面最后新势力的挑战——AWS、Google Cloud、Azure等企业虽推出 GPU 实例,但在订价和性能优化上未能即时符合新的商场需求。
“一个数据中心,若是同期兼顾CPU和GPU的需求,就会变成‘怪神志’。”方磊施展注解称,一方面,若是数据中心仅发轫GPU,要比同期发轫GPU和CPU的成本便宜。据商场信息,如亚马逊的GPU租出价钱为12好意思元/卡时,CoreWeave的价钱则为6好意思元/卡时;另一方面,假如一个瞎想中心不是单纯为GPU高度优化的,也会影响GPU的性能。”
相较传统云厂商“大象难起舞”,专用GPU云企业的成本与交易模式更显“普适性”。如CoreWeave 的 GPU 实例订价,比拟传统云提供商有 50%-80% 的成本上风;九章云极智算云Alaya NeW Cloud的订价战略则抛去了传统裸金属租出方式,忽视“一度算力”按量计费模式,裁减算力使用门槛,普及算力使用的纯真性。
从 CPU 云到 GPU 云的迁徙,不仅是时刻升级,更是瞎想范式从通用向专用的根柢转化,这种转化正重塑着整个云瞎想产业的竞争模式。
算法:深度学习向强化学习跃迁
算法层面的变革也在影响底层算力的跃迁。现时,AI 算法正从数据驱动的深度学习向教养学习转化,这一新的模子锤真金不怕火方式,对GPU专用云的恶果忽视了新条件。
“用于锤真金不怕火大模子的高质地数据量接近天花板,难再有指数级增长。这一甘休促使运筹帷幄者转向强化学习,通过模子与环境交互生成锤真金不怕火数据,以教养响应冲破数据稀缺瓶颈,增强模子的推贤达力。”方磊告诉时期周报记者,算法范式的变化会产生新的算力缺口。原因在于,强化学习的多模子架构大幅增多了锤真金不怕火资源需求。以 70B 参数模子为例,RLHF 阶段约需 48 个 A100 GPU 同期职责,瞎想需求比传统深度学习增多 1-2 个数目级。
"这一数据的判断与英伟达瞎想芯片迭代的推行节律高度吻合——与‘B系列’芯片比拟,其‘R系列’芯片的推感性能达成了十倍乃至百倍的提高。”方磊补充谈。
如何普及GPU专用云的恶果以应答算法的变革?不妨从云瞎想的发展史中领受教养。
近20年,云瞎想产业的发展出现了三个分水岭。一所以凭空化为主要时刻复古的云瞎想崇拜登上历史舞台,应答高速膨胀的移动互联网以及流媒体萌芽所带来的爆炸式瞎想需求;二是池化时刻的变革,通过鸿沟化的革新、编排,酿成了超大鸿沟的瞎想和存储资源池,继而酿成亚马逊云、微软云、阿里云三强鼎峙的模式;三是阿里云翻新性地推出CIPU(云基础方法处理器)架构方式,该架构不仅能在数据中心内弘扬效率,也能和系统内的软硬件深度适配,当瞎想资源、存储资源、集合资源接入CIPU后,就会被云化为凭空算力进行革新编排,兼顾零损耗与高性能。
前两次海浪,使得CPU为中枢的传统X86架构替代了大型机、袖珍机,中意了其时企业业务扩展带来的算力弹性需求,但他们的本色都是通过软件的优化,将越来越多的瞎想节点集合组合对外提供劳动。时至第三次变革,软件的迭代已不及以应答其时的商场需求,架构的翻新成为云厂商换谈超车的新念念路。
通常地,于GPU专用云而言,“软硬一体化”的翻新架构是应答现时算法变化的抓手。方磊告诉时期周报记者,九章智算云从底层时刻架构动身,激动由凭空时刻向Serverless(无劳动)+RL(Reinforcement Learning,强化学习)为主导的架构演变,复古AI部署从“建树机器”转向“提交任务”,从而提高高密度算力需求下的GPU资源的欺诈率。
Serverless+RL的中枢是将传统后端劳动拆解为更细粒度的函数或劳动单位,由云平台自动管制资源、运维和扩展。就如处理饱腹问题,需求正直本需要建厨房、买食材以至雇厨师,而咫尺只需要在外卖平台下单即可。
“在CPU云时期,凭空化时刻通过切片资源让用户使用;GPU云时期,Serverless时刻不错让用户更聚焦应用而非花太多代价去关爱底层优化。让GPU云的提供者更关爱如何作念好AI优化、高密集AI瞎想等,让企业低成本达成他们的贪图。”
“与自动驾驶的AI锤真金不怕火系统访佛,收获于Serverless 架构,九章云极AI新云平台DataCanvas Alaya NeW Cloud能自动完成环境建树、战略加载与任务监控,在强化学习锤真金不怕火中的端到端性能普及5倍。同期,Alaya-UI智能体采样速率普及5-10倍,GPU欺诈率普及2倍。”方磊以为,Serverless会成为GPU云的主要时刻趋势。
(九章云极智能瞎想论坛 受访者供图)
中好意思AI新云分野
在AI云劳动的竞逐中,中好意思两国走出了判然不同的发展旅途。
好意思国AI云商场呈现出典型的成本汇注特征。CoreWeave通过与英伟达的深度妥洽,凭借数百亿好意思元的基础方法进入,构建起50-80%的成本上风;通常领受成本密集战略的Lambda Labs,则以每小时2.49好意思元的H100 GPU租出价钱快速占领学术商场。
不外,上述两家企业的客户靠拢度较高,如CoreWeave跳动60%的收入来自微软单一大客户。这种交易结构虽能保证短期收入快速增长,却也躲避一定业务风险。
中国企业则倾向于通过期刻破局、围绕客户需求提供劳动决策寻求增长。“咱们优化后的GPU欺诈率不错跳动95%,这个数字比许多客户我方优化的终端还要高,而行业平均GPU欺诈率通常为70%傍边。”
此外,中好意思AI云企业的商场定位也存在各别。好意思国的成本驱动模式聚焦大型企业客户,而中国的时刻驱动模式则将眼光投向长尾商场。在生态修复理念方面,前者追求鸿沟与恶果,后者更强调普惠与可络续发展。
方磊以为,数百万企业、数千万个东谈主开拓者,都亟需弹性且高性价比的GPU云劳动。他坦言,咫尺中国智能算力的缺少主要呈现结构性错配的特征。“如某厂商在某一地区缔造了万卡集群,但当地的智能算力需求方可能需要在外地寻找劳动器租用。咫尺公开商场上,大都AI瞎想芯片要么掌合手在头部互联网厂商手中,要么以劳动器(裸金属)的模式出租,商场化的、面向民众的、普惠的智能算力相当稀缺。”
谈及发展贪图,方磊默示,九章云极但愿成为中国NeoCloud的界说者,"此前咱们界说了'一度算力',将来但愿探索出具备中国本性的AIDC运营模式”。他称开云(中国)Kaiyun·体育官方网站-登录入口,DeepSeek-R1的问世已标明,低成本进入能博取优质的模子智力。这也意味着,能否为数千万开拓者提供普惠算力劳动,将成为决定AI云企业竞争力的遑急观望维度。